Setup
1
Select Website as your source
When adding documents to a knowledge folder, choose Website from the available sources.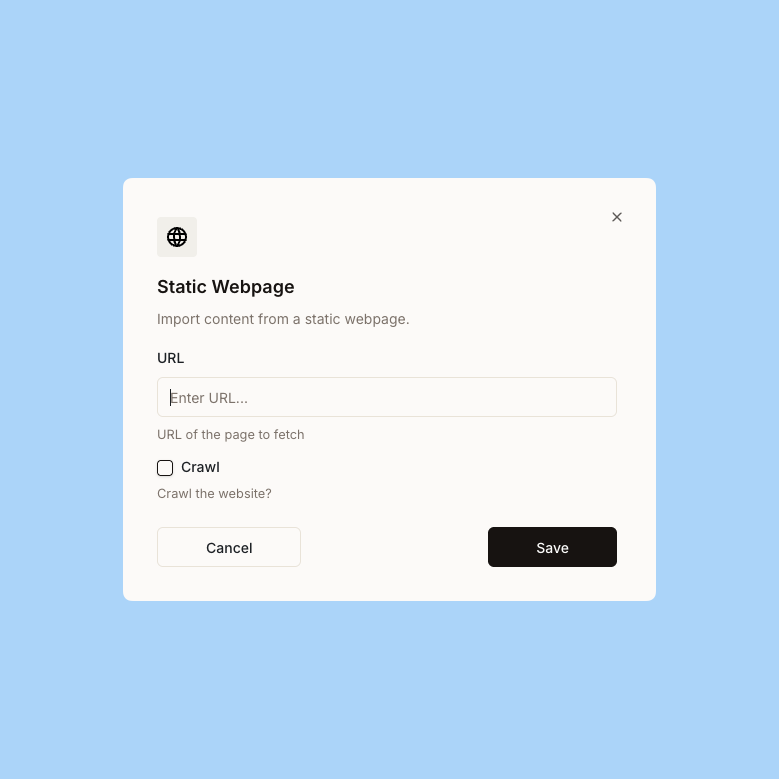
2
Enter the URL
Provide the URL of the webpage you want to import.
3
Import content
Ravenna will scrape and import the content from the specified URL.
How it works
Ravenna uses browser rendering to scrape website content, ensuring accurate extraction of:- Main page content and text
- Formatted content (headings, lists, paragraphs)
- Publicly accessible information
- JavaScript-rendered content
Single page import
Single page import
By default, Ravenna imports content from the single URL you provide. This is ideal for:
- Specific documentation pages
- Help articles
- FAQ pages
- Individual blog posts
Website crawling
Website crawling
Enable crawling to import entire documentation sites automatically:
- Automatic discovery: Ravenna follows links within the same domain to discover and import connected pages
- Breadth-first crawling: Pages are crawled level by level, ensuring comprehensive coverage of your site structure
- Page limit: Ravenna crawls a maximum of 100 pages to prevent overloading your website
- Folder structure: Crawled sites are organized under a root folder named after the domain
- Same-domain only: Crawling stays within the original domain to avoid importing external content
Crawling respects the same domain as the starting URL. External links are automatically filtered out.
Requirements
- The website must be publicly accessible (no authentication required)
- Content must be available without login or paywalls
Managing imported content
After import, you can:- Archive pages to exclude them from AI responses
- Move pages from your knowledge folder
Auto sync
When auto-sync is enabled, Ravenna keeps your website content up-to-date:- Page content is re-scraped during sync to capture updates
- Changes to the webpage are reflected in your knowledge base
- If the page becomes unavailable, the sync will fail and you’ll be notified
Auto-sync for websites re-scrapes the same URL to check for updates. It does not discover new pages or follow links.